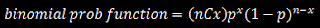Technical analysts believe in the following:
- that history repeats itself, so look for trends
- trends persist over an appreciable length of time
- value and prices are determined by supply and demand
- causes are difficult to determine but shifts in supply/demand reveal themselves in market pirce behaviour
Efficient Market Hypothesis (EMH) analysts are opposed and believe:
- market prices follow a random (unpredictable) walk
- new information gets immediately priced in
- that technicians are wasting their time; too subjective and looking for past trends that never reoccur the same way
Fundamentalists are more in the technical camp but they believe that causes for price behaviour can be observed through analysing earnings and publicly available data - that the economic fundamentals such as return vs. risk determine market prices
- Technicians look for a price move; expect price move to happen fairly quickly as new data is observed and processed by the market
- Fundamentalists look for why the price will move; expect price move to happen slowly
- EMH analysts that when price shifts happen, the happen rapidly - instant digesting of new information by the market
Technical analysis pros:
- quick/easy
- no accounting data needed
- incorporates pyschological and economic reasons
- tells you when to buy (but not why)
- too subjective
- historical relationships may not be repeated
- EMH belief that models cannot predict random price walk
- technical trading rules would be self-fulfilling
- if successful, trading rules would be copied and erase the arbitrage
Four classes of technical trading rules/indicators:
- contrarian = opposite of what majority is doing
- smart money followers = buy when smart money buys, sell when it sells
- momentum indicators = when market moves in a direction, buy/sell with it
- price-and-volume = look for significant corresponding movements in both price and volume and act accordingly
Contrarian Opinion Rules
- Cash position of mutual funds if mutual fund cash ratio (mut.fund cash/total assets) is high(>11%) then funds are bearish (so contrarians buy). If low (<4%)>
- Investor credit balances in brokerage accounts Falling credit balances mean normal investors are bullish and buying (so contrarians sell)
- Opinions of investment advisory services if bearish sentiments index is high (>60%) then contrarians buy.
- OTC vs. NYSE volume OTC are more speculative. A high ratio of OTC to NYSE means normal investors are bullish (so contrarians sell).
- CBOE put/call ratios If ratio is high (>0.6) then most normal investors are trying to sell, so contrarians buy. Low (<0.4)>
- Stock index futures When future traders are bullish (>70%) then contrarians sell.
Smart money rules
three indicators:
- Confidence Index (CI) by Barrons = ratio of yields on high grade bonds to yields on broader (riskier) bonds. So if CI is high, investors are confident and are selling high grade bonds to buy better earning lower grade bonds. If CI is up, smart money investors are buying.
- TED - T-Bill/eurodollar yield spread - spreads widen during crisis, flight to Treasuries. Smart money is bearish.
- Debit balances in brokerage accounts (margin debt) - if margin debt is high, smart money is buying (bullish).
Momentum indicators
Breadth of market
- indices represent a few, large companies
- market has many medium/small companies
- index may go one way while smaller issues go the other way
- comparing advance-decline line and index - if they move together, then there is a broad market movement
Stocks above their 200 day moving average
- if over 80% of stocks trade above their 200 day avg then the market is overbought (therefore bearish). if 20% are above 200 day avg then market is oversold (therefore bullish)
Stock Price and Volume Techniques
- Dow Theory = stock prices move in trends: major trends, intermediate trends, short-run movement. Technicians look for reversals and recoveries in major market trends
- Volume price changes on high volume tell us whether suppliers or demanders are driving change.
- upside/downside volume ratio = vol. of stocks that increased/vol. of stocks that declined
- If ratio is 1.75 or more, market is overbought (bearish). If less than 0.75 then market is oversold (bullish)
- Support/resistence levels most stock prices are stable; fluctations up hit resistence, flux down receives support
- Moving average line trends again. Random flux masks trends. By using moving averages (10 to 200 days) true trends will appears amongst the noise of randomness
- Relative strength = stock price/market index value i.e. is a stock outperforming the market (positive trend) or underperforming relative to market